Characters get complex

I originally posted this in 2016 and thought it still resonated today.
Characters
Characters have been the life blood of communications between people since the creation of written language. Limited sets of characters have been key to simple printing and communication with humans via machines. For example, English only having 26 characters was easy to translate into machines that print or display words. Adding a limited number of other characters makes English complete for machine interfaces. Ten digits for numbers and a handful of punctuation marks and you can write anything. English thus had an advantage for machine use over languages with larger symbol counts.
We can look at the history of character sets can see how things have progressed over time. The movable press systems had a limited number of blocks with variety being driven by artistic flare more than communication. Capitalization adds 26 more symbols. Special characters for the start of paragraphs added flare, as did emphasis using italics. In each case the information content did not significantly increase (if at all), but it made things easier on the readers eyes. A text that someone enjoys reading increases the probability of information being exchanged, so it was well worth the increased cost and complexity.
Electricity requires more than ink
As we move from ink on paper to data in electric form we see a swing in the other direction. Morse code is probably the earliest one of these that is still widely known today. By limiting the set of symbols to 26 letters and 10 digits messages could be sent using manually tapped messages using just a spark. Operators having very few symbols to remember could achieve high data rates for a hand encoded system. A trained listener can copy 40-60 words per minute.

As more characters were added to Morse code the symbols became more complex. The original American version had short sets of dots (short) and dashes (long) impulses as demonstrated in this file by user Emilhem on wikipedia. Punctuation and accented characters increased the symbol set and made it more complex and longer to transmit words (more symbols are required for each sentence on average now). Languages like Chinese require so many symbols to represent the words that they translate the characters into a 4 digit code that is then translated into Morse code. It is fairly obvious that at that point the system is essentially at a breaking point.
Digital starts by simplifying
Machines don’t like a varying length in representing symbols (at least not until we get to Huffman coding, but that will be another entry), so as humans transitioned from keys and pencils to teletypes, new character sets were born. Taking earlier codes that were similar to Morse code, Emile Baudot created a 5 bit code in 1870. After a handful of variations, the most prominent by Donald Murray it became a standard of telecommunications for decades.
With 5 bits the letters can all be represented, but that only leaves 6 places for numbers, punctuation and control codes. The engineering solution that made BAUDOT successful was a shift. The sequence 11011 shifted the receiver into “figures”, while a 11111 shifted the receiver into “letters”. In most cases the sender would spend multiple characters, if not whole lines in each of these. By having the space, carriage return and line feed in both modes the shift characters did not have to occur very often. This saved on transmission overhead, and for machines that physically shifted mechanical assemblies it probably reduced overall maintenance.
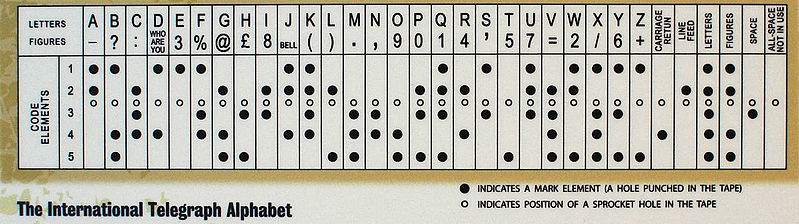
As our communications systems became faster we designed systems that were simpler to use. As the world settled on 8 bits being in a byte (or sometimes 7 when parity is used) shifted character sets were replaced by ones that had a single binary representation. The two most successful were ASCII and EBCDIC. While EBCDIC saw wide adoption due to the success of the IBM System/360 mainframe, but never saw wide usage outside of that ecosystem. Non contiguous runs of characters made it harder to use in software (although it can be argued not always in hardware).
ASCII
ASCII appeared on the scene in 1963 just as the number of character sets were reaching a dangerous peak. As the product of the American Standards Association (now known as American National Standards Institute, or ANSI) it carried a lot of weight. More importantly, it was a full solution in the American market and it was easy to work with on a wide range of machines. For English it was a remarkable success that became the foundation of decades of work and of every character set to see wide adoption.
Using 7 bits it could have all of the printable characters in literate English along with control codes for screens and printers. There were characters to control flow (XON/XOFF so a receiver could request a pause saw use well into the 1990’s), record markings and even a bell (Fun fact: many systems still honor the bell as a Control-G, and you can have text make a sound. When you annoy others with that, you didn’t hear it here). Many of the system specific adoptions traded the 8th parity bit for extended characters that spurred early graphics, but none of those ever reached a standard usage.
During the 4 decades of ASCII being the top dog, the rest of the world went from custom systems to ASCII kludges with varying levels of success. Encoding could be switched to make a machine type and display in non English characters, but the result was hard to work across machines and manage. As the world became interconnected these alternate “code pages” became virtual walls between different users.
UNICODE
The International Organization for Standards (ISO) started to work on a single solution in 1989. The results along the way have gone by different names, but Unicode has stuck and is pretty much the accepted one. The standards committee worked under the assumption that characters would have to be wider in memory. There were variations that require 2 bytes and 4 bytes. The 2 byte versions, known as UTF-16 became the most widely used of those with adoption by Microsoft across applications and libraries. The 4 byte version was very easy to work with but stressed the limited memory and storage of the day, thus it is uncommon to see UTF-32.
While 16 bits can represent most of the world’s symbols, it was woefully small for some of the Asian languages that represent the largest populations. With the 2 byte standard already being firmly entrenched in library implementations, a solution was required that didn’t blow up the memory layouts currently in use. In version 2 of Unicode the standards bodies brought back the concept of shift to add hundreds of thousands of symbols. A single 2 byte value would shift to a different character set for the next 2 bytes. So characters can be 2 or 4 bytes long. The problem is that it now has become too complex to work with easily or quickly, but at the same time it has become entrenched.
So some of the problems with UTF-16 include:
- It can be in either Byte Endianess. (The order of the bytes can switch.)
- To keep the Endianess straight, there is a Byte Order Mark or BOM.
- When the BOM is lost, the characters are not deterministic (although it isn’t a lost cause in most cases).
- Text from different sources might need to shift byte order or re-encode the whole string.
- Characters can be different lengths. You have to parse the whole string to know the number of characters.
- All strings require twice, or more memory as ASCII.
You should be asking yourself, “What did we get ourselves into?” right about now. Don’t worry, it gets more complex. Too complex for this blog entry. The good news is that most applications, programming languages and libraries take care of these things and we can mostly remain ignorant. That is until we need to look under the covers or communicate between wildly different systems (see the bulleted list above).
Unicode is actually more than the UTF-16LE/BE and UTF-32 representation. There are extensions of EBCDIC (UTF-EBCDIC, which you may never run across). In 1992, Ken Thompson and Rob Pike came up with a solution that was ASCII compatible, storage and CPU efficient and didn’t care about machine byte order. It is called UTF-8 and it made the Internet Unicode compliant.
UTF-8 starts with 7 bit ASCII (now called UTF-7 by some people). Notice the most significant, or sign bit is always 0 in ASCII. UTF-8 says when that bit is a 1 you have more than 1 byte. The number of bits that are 1s before a zero is the number of bytes used. Each byte following starts with a 10 to denote it is part of a character already started. A program can count characters by scanning for bit masks and skipping quickly. The minimum number of bytes are always used, and older systems could handle Unicode with minor alternations (sometimes none).
Using 6 bytes UTF-8 can represent 2 billion symbols, but UTF-16 got jealous and forced it to end at the point of just over 1 million (UTF-16 causes everyone heartburn). This limitation means we never see 5 or 6 byte UTF-8 and 4 byte sequences are only half used. The good news, is that any system that handles UTF-8 can talk to any other UTF-8 system. English ASCII systems can still communicate with these systems in many cases that makes for a great backwards compatible win.
So now that we have more than 1 million symbols, what do we use them for? First off, we can represent almost all of the human language symbols. That has been done and then things got a little out of hand. Now there are encodings for dead languages, fictional species (Tolkien runes and Klingon), and Emoji. Have we created a beast? I don’t know if Star Trek, a DVD icon, or Elvish will be useful to convey meaning past the modern day, but at the same time an Emoji for a pile of poop is almost timeless in conversation. That is if a future culture could ever decode Unicode and have the mapping to the myriad of alternate symbol mappings.
I don’t hold out much hope that any of the Unicode options are appropriate for archiving information past a few centuries. The peculiarities and mappings are too likely to be lost as systems shift into other encoding formats. I know that many involved in the ISO standards effort may disagree, but I’ll cover the issues as I see them in future entries.